Improving performance: non-blocking processing of streams
Concurrency, Java, Java8 ·Imagine we have an application that needs to access an external web service in order to gather information about clients and then process it. More specifically, we can’t get all this information in a single invocation. If we want to look up different clients, we will need several invocations.
As shown in the graphic below, the example application will retrieve information about several clients, group them in a list and then process it to calculate the total amount of its purchases:
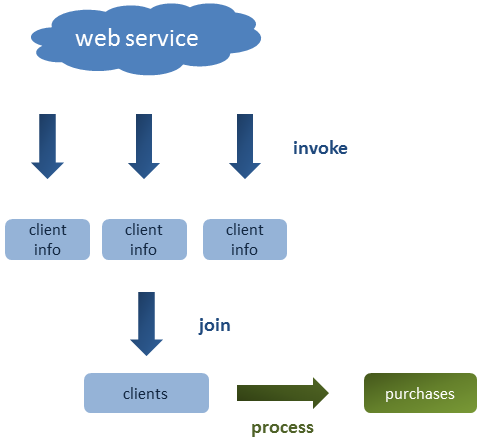
In this post, we will see different ways of gathering the information and which one is the best in terms of performance.
This is a Java related post. However, we will use the Spring framework to invoke a RESTful web service.
Sections
- Explaining the example
- First attempt: Sequential stream
- Improving performance: Parallel stream
- Non-blocking processing with CompletableFuture
- Conclusion
The source code can be found at the Java 8 GitHub repository.
Additionally, you can access the source code of the web application exposing the RESTful web service at this repository.
1 Explaining the example
In our application, we have a list of 20 ids representing clients we want to retrieve from a web service. After retrieving all the clients, we will look up at what did every client purchase and sum them up to compute what is the total amount of money spent by all the clients.
There is one problem though, this web service only allows to retrieve one client at each invocation, so we will need to invoke the service twenty times. In addition, the web service is a little bit slow, taking at least two seconds to respond to a request.
If we take a look at the application implementing the web service, we can see that invocations are handled by the ClientController class:
@RestController
@RequestMapping(value="/clients")
public class ClientController {
@Autowired
private ClientService service;
@RequestMapping(value="/{clientId}", method = RequestMethod.GET)
public @ResponseBody Client getClientWithDelay(@PathVariable String clientId) throws InterruptedException {
Thread.sleep(2000);
Client client = service.getClient(clientId);
System.out.println("Returning client " + client.getId());
return client;
}
}
A Thread.sleep is used to simulate the slowness in responding.
The domain class (Client) contains the information we need; how much money has a client spent:
public class Client implements Serializable {
private static final long serialVersionUID = -6358742378177948329L;
private String id;
private double purchases;
public Client() {}
public Client(String id, double purchases) {
this.id = id;
this.purchases = purchases;
}
//Getters and setters
}
2 First attempt: Sequential stream
In this first example we will sequentially invoke the service to get the information of all twenty clients:
public class SequentialStreamProcessing {
private final ServiceInvoker serviceInvoker;
public SequentialStreamProcessing() {
this.serviceInvoker = new ServiceInvoker();
}
public static void main(String[] args) {
new SequentialStreamProcessing().start();
}
private void start() {
List<String> ids = Arrays.asList(
"C01", "C02", "C03", "C04", "C05", "C06", "C07", "C08", "C09", "C10",
"C11", "C12", "C13", "C14", "C15", "C16", "C17", "C18", "C19", "C20");
long startTime = System.nanoTime();
double totalPurchases = ids.stream()
.map(id -> serviceInvoker.invoke(id))
.collect(summingDouble(Client::getPurchases));
long endTime = (System.nanoTime() - startTime) / 1_000_000;
System.out.println("Sequential | Total time: " + endTime + " ms");
System.out.println("Total purchases: " + totalPurchases);
}
}
Output:
Sequential | Total time: 42284 ms
Total purchases: 20.0
The execution of this program takes 42 seconds approximately. This is too much time. Let’s see if we can improve its performance.
3 Improving performance: Parallel stream
Java 8 allows us to split a stream into chunks and process each one in a separate thread. What we need to do is simply create the stream in the previous example as a parallel stream.
You should take into account that each chunk will be executed in its thread asynchronously, so the order in which the chunks are processed must not matter. In our case, we are summing the purchases, so we can do it.
Let’s try this:
private void start() {
List<String> ids = Arrays.asList(
"C01", "C02", "C03", "C04", "C05", "C06", "C07", "C08", "C09", "C10",
"C11", "C12", "C13", "C14", "C15", "C16", "C17", "C18", "C19", "C20");
long startTime = System.nanoTime();
double totalPurchases = ids.parallelStream()
.map(id -> serviceInvoker.invoke(id))
.collect(summingDouble(Client::getPurchases));
long endTime = (System.nanoTime() - startTime) / 1_000_000;
System.out.println("Parallel | Total time: " + endTime + " ms");
System.out.println("Total purchases: " + totalPurchases);
}
Output:
Parallel | Total time: 6336 ms
Total purchases: 20.0
Wow, that’s a big improvement! But what does this number come from?
Parallel streams internally use the ForkJoinPool, which is the pool used by the ForkJoin framework introduced in Java 7. By default, the pool uses as many threads as your machine’s processors can handle. My laptop is a quad core that can handle 8 threads (you can check this by invoking Runtime.getRuntime.availableProcessors), so it can make 8 invocations to the web service in parallel. Since we need 20 invocations, it will need at least 3 “rounds”:
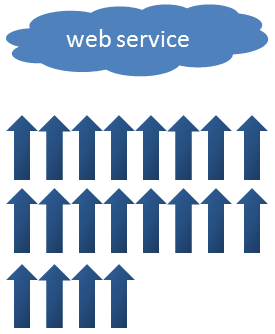
Ok, so from 40 seconds to 6 is quite a good improvement but, can we still improve it further? The answer is yes.
4 Non-blocking processing with CompletableFuture
Let’s analise the previous solution.
We send 8 threads invoking each one the web service, but while the service is processing the request (two whole seconds), our processors are doing nothing but waiting (this is a IO operation). Until these requests don’t come back, we won’t be able to send more requests.
The question is, what if we could send all 20 requests asynchronously, freeing our processors and process each response when is available? This is where CompletableFuture comes to the rescue:
public class AsyncStreamExecutorProcessing {
private final ServiceInvoker serviceInvoker;
private final ExecutorService executorService = Executors.newFixedThreadPool(100);
public AsyncStreamExecutorProcessing() {
this.serviceInvoker = new ServiceInvoker();
}
public static void main(String[] args) {
new AsyncStreamExecutorProcessing().start();
}
private void start() {
List<String> ids = Arrays.asList(
"C01", "C02", "C03", "C04", "C05", "C06", "C07", "C08", "C09", "C10",
"C11", "C12", "C13", "C14", "C15", "C16", "C17", "C18", "C19", "C20");
long startTime = System.nanoTime();
List<CompletableFuture<Client>> futureRequests = ids.stream()
.map(id -> CompletableFuture.supplyAsync(() -> serviceInvoker.invoke(id), executorService))
.collect(toList());
double totalPurchases = futureRequests.stream()
.map(CompletableFuture::join)
.collect(summingDouble(Client::getPurchases));
long endTime = (System.nanoTime() - startTime) / 1_000_000;
System.out.println("Async with executor | Total time: " + endTime + " ms");
System.out.println("Total purchases: " + totalPurchases);
executorService.shutdown();
}
}
Output:
Async with executor | Total time: 2192 ms
Total purchases: 20.0
It took a third of the time spent in the previous example.
Explanation
We sent all 20 requests at the same time, so the time spent in IO operations is spent only once. As soon as responses come by, we process them quickly.
It is important the use of the executor service, set as an optional second parameter of the supplyAsync method. We specified a pool of a hundred threads so we could send 100 requests at the same time. If we don’t specify an executor, the ForkJoin pool will be used by default.
You can try to remove the executor and you will see the same performance as in the parallel example.
5 Conclusion
We have seen that when executing operations that do not involve computing (like IO operations) we can use the CompletableFuture class to take advantage of our processors and improve the performance of our applications.
I’m publishing my new posts on Google plus and Twitter. Follow me if you want to be updated with new content.